

Firstly, “Dealing with categorical features with high cardinality: Feature Hashing”, is an interesting question. So, this post will be interesting and will help a lot of learners.
Introduction to Feature Hashing
Generally, many machine learning algorithms are not able to use non-numeric data. So, we represent these features using strings. And we need some way of transforming them into numbers before using scikit-learn’s algorithms. Also, we call the different ways of doing these encodings.
Must be remembered, categorical data can pose a serious problem if they have high cardinality i.e too many unique values.
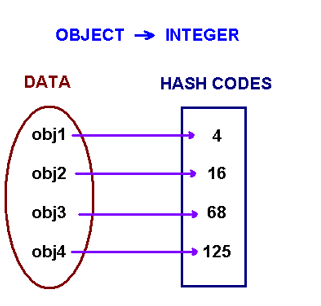
In fact, the central part of the hashing encoder is the hash function, which maps the value of a category into a number. For example, a (Give it a name: “H1”) hash function might treat “a=1”, “b=2”, “c=3”, “d=4” ……
Then, sum all the values together of the label together.
hash("abc") = 1+ 2+ 3 = 6 # H1 hash function
Specifically, feature hashing maps each category in a categorical feature to an integer within a pre-determined range. Even if we have over 1000 distinct categories in a feature and we set b=10 as the final feature vector size (a pre-determined range), the output feature set will still have only 10 features as compared to 1000 binary features if we used a one-hot encoding scheme.
Hash functions also come with a not-so-nice side effect i.e. they can hash different keys to the same integer value (we call it ‘collision’). It will certainly happen in this case as we had represented 1000 distinct categories as 10 columns.
You have to do a trade-off between no. of categories getting mapped to the same integer value(% of collision) and the final feature vector size (b i.e. a pre-determined range). Here, b is nothing but n_components.
So, the idea of “feature hashing”:
Convert data into a vector of features. Generally, this is done using hashing. Specifically, we call the method “feature hashing” or “the hashing trick”.
How does feature hashing work?
To explain, let’s look at a simple example using text as data.
So, let’s say our text is: “Everything is planned”
We would like to represent this as a vector. The first thing, we need to fix is the length of the vector, and the number of dimensions, we are going to use, let’s say we would like to use 5 dimensions (n_components, discussed below: how to use this parameter in python).
Once we fix the number of dimensions we need a hash function (hash_method, discussed below: how to use this parameter in python) that will take a string and return a number between 0 and n-1, in our case between 0 and 4. We can use any good hash function and you just used h(string) mod n to make it return a number between 0 and n-1.
I’ll invent the results for each word in our text:
Please note that for a given number the remainder can only be 0 to n-1. So if we divide any number by 5 the remainder can only be 0,1,2,3 or 4.
h(everything) mod 5 = 0
h(is) mod 5 = 1
h(well) mod 5 = 1
h(planned) mod 5 = 3
Once we have this we can simply construct our vector as:
(0,1,1,3)
Example of Feature Hashing
Another example is a pictorial representation:
n_components=8 and hash Function= Murmurhash3
The index value here is nothing but a reminder. Every index value becomes the feature for the given dataset. You will see in the last section (Example: Python Code) of this article that we have 8 new columns generated out of a categorical column: col_0 to col_7.
We can represent the index 0 to 7 (shown in the above image) as col_0 to col_7 with possible contained values as 1 or 0 i.e. 8 columns that contain binary values.
In the above image, “Sentence” is a categorical column.
Replace “Sentence” with col_0 to col_7 [index 0 to 7] which contains either 1 or 0.
Run the code snippet provided in the last section, interpret the results i.e. transformation/encoding, and reread the article if things are not crystal clear.
Python library for feature hashing
A Python library comes to the rescue:
A set of scikit-learn-style transformers for encoding categorical variables into numeric with different techniques. Ref: https://pypi.org/project/category-encoders/
From this library: http://contrib.scikit-learn.org/category_encoders , we have a class (A reference python code is present in the last portion of this article):
classcategory_encoders.hashing.HashingEncoder(max_process=0, max_sample=0, verbose=0, n_components=8, cols=None, drop_invariant=False, return_df=True, hash_method=’md5′) [source]
It has two important arguments:
hash_method: str
which hashing method to use. Any method from hashlib works.
You can use a hashing algorithm(hash function or method) of your choice; the default is “md5”.
n_components: int
how many bits to use to represent the feature. By default we use 8 bits. For high-cardinality features, consider using up-to 32 bits.
The advantage of this encoder is that it does not maintain a dictionary of observed categories. Consequently, the encoder does not grow in size and accepts new values during data scoring by design.
You want interpretability for the contribution of each of your levels. You won’t be able to give a good answer.
Indeed, categorical features with high cardinality is tricky.
Python code for feature hashing
Example: Python Code
from category_encoders.hashing import HashingEncoder
import pandas as pd
from sklearn.datasets import load_boston
bunch = load_boston()
X = pd.DataFrame(bunch.data, columns=bunch.feature_names)
y = bunch.target
he = HashingEncoder(cols=[‘CHAS’, ‘RAD’]).fit(X, y)
data = he.transform(X)
print(data.info())
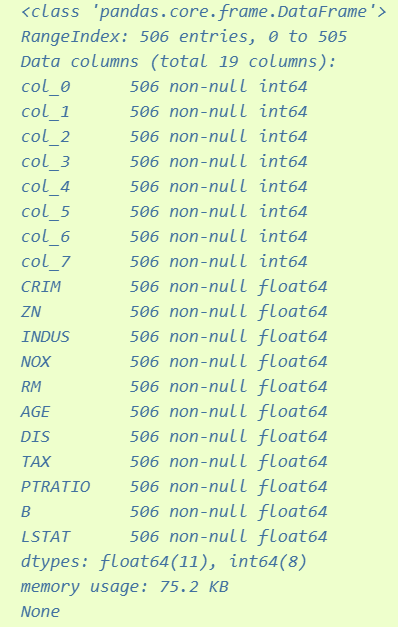
The code first imports the HashingEncoder from the category_encoders package and pandas package. It then imports the Boston Housing dataset using load_boston() from the sklearn.datasets package and stores the data in bunch.
The code creates a pandas DataFrame X using the dataset’s data and feature names, and y using the target values.
Next, the HashingEncoder is initialized with cols parameter set to [‘CHAS’, ‘RAD’]. Then, it is fitted on the data using fit(X, y).
Finally, the HashingEncoder is used to transform X into a new DataFrame data that has the same number of rows as the original DataFrame X, but with a reduced number of columns. data is printed with information about the new DataFrame columns using the info() method.
Conclusion
We should take care of categorical features with high cardinality properly while exploring data. We discussed the following:
- What is category encoding?
- Need for category encoding
- What is feature hashing?
- How does feature hashing work?
- Python library and example Python code for feature hashing.
I highly recommend checking out this incredibly informative and engaging professional certificate Training by Google on Coursera:
Google Advanced Data Analytics Professional Certificate
There are 7 Courses in this Professional Certificate that can also be taken separately.
- Foundations of Data Science: Approx. 21 hours to complete. SKILLS YOU WILL GAIN: Sharing Insights With Stakeholders, Effective Written Communication, Asking Effective Questions, Cross-Functional Team Dynamics, and Project Management.
- Get Started with Python: Approx. 25 hours to complete. SKILLS YOU WILL GAIN: Using Comments to Enhance Code Readability, Python Programming, Jupyter Notebook, Data Visualization (DataViz), and Coding.
- Go Beyond the Numbers: Translate Data into Insights: Approx. 28 hours to complete. SKILLS YOU WILL GAIN: Python Programming, Tableau Software, Data Visualization (DataViz), Effective Communication, and Exploratory Data Analysis.
- The Power of Statistics: Approx. 33 hours to complete. SKILLS YOU WILL GAIN: Statistical Analysis, Python Programming, Effective Communication, Statistical Hypothesis Testing, and Probability Distribution.
- Regression Analysis: Simplify Complex Data Relationships: Approx. 28 hours to complete. SKILLS YOU WILL GAIN: Predictive Modelling, Statistical Analysis, Python Programming, Effective Communication, and regression modeling.
- The Nuts and Bolts of Machine Learning: Approx. 33 hours to complete. SKILLS YOU WILL GAIN: Predictive Modelling, Machine Learning, Python Programming, Stack Overflow, and Effective Communication.
- Google Advanced Data Analytics Capstone: Approx. 9 hours to complete. SKILLS YOU WILL GAIN: Executive Summaries, Machine Learning, Python Programming, Technical Interview Preparation, and Data Analysis.
It could be the perfect way to take your skills to the next level! When it comes to investing, there’s no better investment than investing in yourself and your education. Don’t hesitate – go ahead and take the leap. The benefits of learning and self-improvement are immeasurable.
Here are some additional articles that you might find interesting or helpful to read:
- A creative way to deal with class imbalance (without generating synthetic samples)
- Curse of Dimensionality: An Intuitive and practical explanation with Examples
- Regression Imputation: A Technique for Dealing with Missing Data in Python
- How to generate and interpret a roc curve for binary classification?
- Linear Regression for Beginners: A Simple Introduction
- Linear Regression, heteroskedasticity & myths of transformations
- Bayesian Linear Regression Made Simple with Python Code
- Logistic Regression for Beginners
- Understanding Confidence Interval, Null Hypothesis, and P-Value in Logistic Regression
- Logistic Regression: Concordance Ratio, Somers’ D, and Kendall’s Tau
Check out the table of contents for Product Management and Data Science to explore those topics.
Curious about how product managers can utilize Bhagwad Gita’s principles to tackle difficulties? Give this super short book a shot. This will certainly support my work.