

This post, “Machine Learning Landscape 102”, will answer the following questions:
- What is unsupervised learning?
- What is semi-supervised learning?
- What is reinforcement Learning?
The last post, “Machine Learning Landscape 101“, tried to answer the following questions:
- Where does Machine Learning start and where does it end?
- What exactly does it mean for a machine to learn something?
- What are the types of Machine Learning?
- What is supervised learning?
Together, these two posts offer a solid foundation for anyone looking to gain a deeper understanding of machine learning and its various applications.
Unsupervised Machine Learning
Unsupervised learning is a type of machine learning in which models are trained using unlabeled dataset and are allowed to act on that data without any supervision.
No labels are given to the learning algorithm, leaving it on its own to find structure in its input.

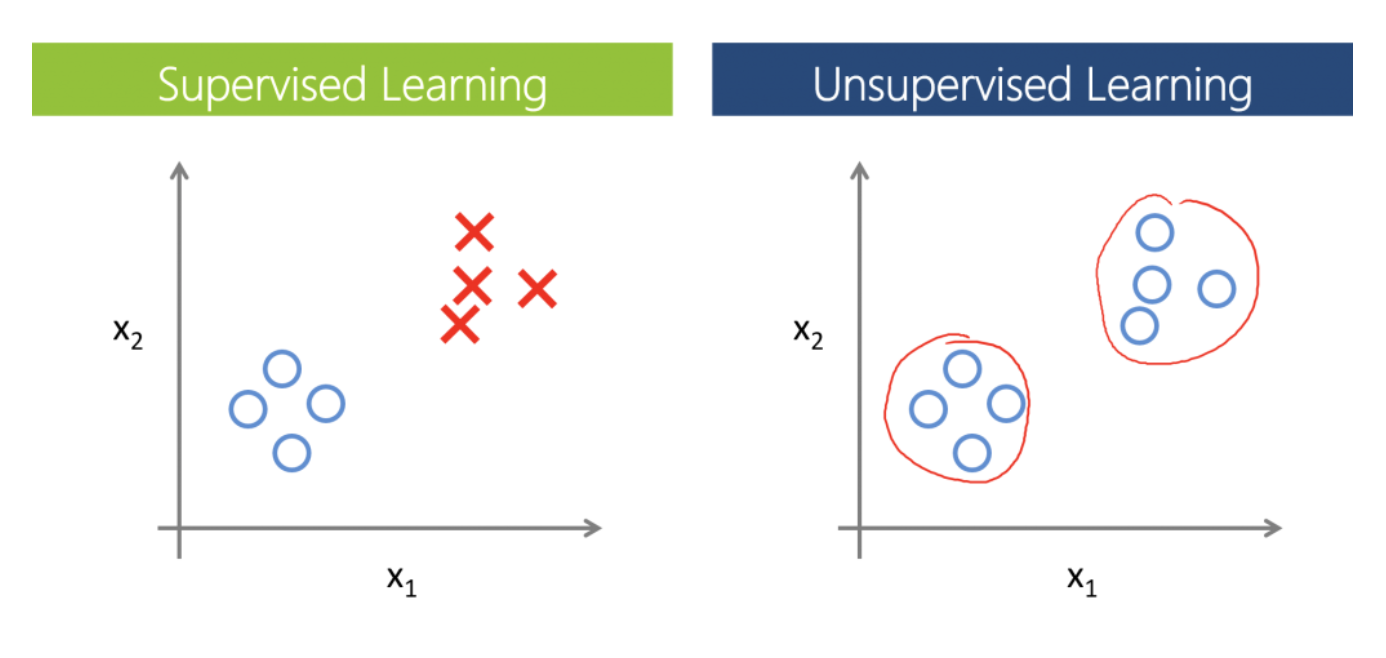
In the above example, the RHS (Right Hand Side) image does not contain label information (Assume labels are colors: Blue or Red). Still we are able to group them basis features x1 & x2. There is no name for the group, simply these are two groups.
Example:
Suppose the unsupervised learning algorithm is given an input dataset containing images of different types of cats and dogs.
The algorithm is never trained upon the given dataset, which means it does not have any idea about the features of the dataset.
The task of the unsupervised learning algorithm is to identify the image features on their own.
An unsupervised learning algorithm will perform this task by clustering the image dataset into groups according to similarities between images.
Some applications of Unsupervised Machine Learning techniques
Clustering:
- It allows you to automatically split the dataset into groups according to similarity.
- Often, however, cluster analysis overestimates the similarity between groups and doesn’t treat data points as individuals.
- For this reason, cluster analysis is a choice for applications like customer segmentation and targeting.
Anomaly detection:
- It can automatically discover unusual data points in your dataset.
- This is useful in pinpointing fraudulent transactions, discovering faulty pieces of hardware, or identifying an outlier caused by a human error during data entry.
Association mining:
- It identifies sets of items that frequently occur together in your dataset.
- Retailers often use it for basket analysis
- Because it allows analysts to discover goods often purchased at the same time and develop more effective marketing and merchandising strategies.
Latent variable models:
- These are commonly used for data preprocessing
- Such as reducing the number of features in a dataset (dimensionality reduction)
- Decomposing the dataset into multiple components.
Semi-Supervised Machine Learning
Supervised machine learning algorithms learn from a dataset with the outcome variable. Unsupervised machine learning algorithms learn from a dataset without the outcome variable.
In semi-supervised learning: An algorithm learns from a dataset that includes both labeled and unlabeled data, usually mostly unlabeled.
Example:
- When you don’t have enough labeled data to produce an accurate model and When you don’t have the ability or resources to get more data, you can use semi-supervised techniques to increase the size of your training data.
- You can use a semi-supervised learning algorithm to label the data and retrain the model with the newly labeled dataset.
Reinforcement Machine Learning
In supervised learning, the training data has the answer key with it so the model is trained with the correct answer itself.
- There is no answer but the reinforcement agent decides what to do to perform the given task.
- In the absence of a training dataset, it is bound to learn from its experience.
Supervised learning is when a model learns from a labeled dataset with guidance.
- EXAMPLE – “I know how to classify this data, I just need you (the model) to do this task.”
- USAGE – To classify labels or to produce real numbers
Whereas reinforcement learning is when a machine or an agent interacts with its environment, performs actions, and learns by a trial-and-error method.
- EXAMPLE – “I don’t know how to ACT in this environment, can you find a good policy/behavior and meanwhile I’ll give you feedback.”
- USAGE – To find an optimal policy that maximizes the reward for the model/agent
Conclusion
The last post, “Machine Learning Landscape 101”, delved into the starting and ending points of machine learning, the meaning of machine learning, and the types of machine learning, specifically focusing on supervised learning.
This post, “Machine Learning Landscape 102“, covered the remaining types of machine learning, including unsupervised learning, semi-supervised learning, and reinforcement learning, providing a comprehensive overview of the machine learning landscape.
Check out the table of contents for Product Management and Data Science to explore those topics.
Curious about how product managers can utilize Bhagwad Gita’s principles to tackle difficulties? Give this super short book a shot. This will certainly support my work.
AI is fun! Thanks a ton for exploring the AI universe by visiting this website.