

Through this blog, we will try to answer: “What is data distribution in machine learning?”. This blog post explores the concept of data distribution in data science. Understanding data distribution is a critical aspect of data analysis and visualization.
A distribution is simply a collection of data, or scores, on a variable. Usually, these scores are arranged in order from smallest to largest and then they can be presented graphically.
Page 6, Statistics in Plain English, Third Edition, 2010.
Frequency Distribution
Suppose we have some items. Frequency Distribution: values and their frequency (how often each value occurs).
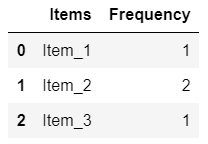
Let’s plot (X-axis: values) the above table:
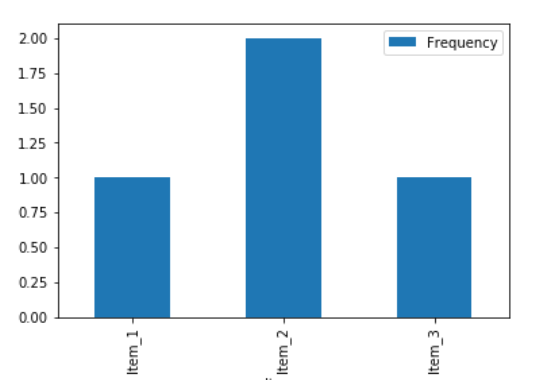
The values above are discrete, suppose we have a continuous variable at X-axis, then we can represent using a curve.
If we superimpose a smooth curve on frequency distribution to accommodate continuous nature, the plot will look like this:
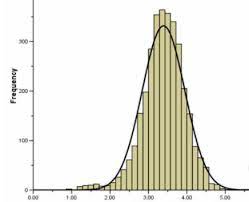
A distribution in statistics is a function that shows the possible values for a variable and how often they occur.
Probability distribution
A frequency distribution gives us an idea about how frequently a given data point occurs and how probable it is to occur.
While a frequency distribution gives the exact frequency or the number of times a data point occurs, a probability distribution gives the probability of occurrence of the given data point.
When the number of test cases are large, the frequency distribution and the probability distributions are similar in shape. One could say that the relative frequency distribution is a data-dependent proxy for the underlying probability distribution.
Let’s discuss a term:
A random variable is a numerical description of the outcome of a statistical experiment.
For instance, a random variable representing the number of automobiles sold at a particular dealership on one day would be discrete, while a random variable representing the weight of a person in kilograms (or pounds) would be continuous.
Discrete and continuous distributions
In probability distribution also, we have discrete and continuous distributions.
A discrete distribution displays the probabilities of the outcomes of a random variable with finite values and is used to model a discrete random variable. In discrete distributions, the values of the random variable are countable.
Let us now extend the concept of distribution to continuous variables again.
In general, distributions for continuous variables are called continuous distributions. Continuous distributions measure something, rather than just count. These types of random variables are uncountable. They also carry the fancier name probability density.
Each of the distributions, whether continuous or discrete, has different corresponding formulas that are used to calculate the expected value or mean of the random variables.
Conclusion
Hope this article had helped in finding an answer to “What is data distribution in machine learning?”. In conclusion, having a thorough understanding of data distribution is essential for effective data analysis and visualization. By knowing the type of data distribution, one can choose the appropriate statistical tools and methods to draw accurate conclusions from data.
I highly recommend checking out this incredibly informative and engaging professional certificate Training by Google on Coursera:
Google Advanced Data Analytics Professional Certificate
There are 7 Courses in this Professional Certificate that can also be taken separately.
- Foundations of Data Science: Approx. 21 hours to complete. SKILLS YOU WILL GAIN: Sharing Insights With Stakeholders, Effective Written Communication, Asking Effective Questions, Cross-Functional Team Dynamics, and Project Management.
- Get Started with Python: Approx. 25 hours to complete. SKILLS YOU WILL GAIN: Using Comments to Enhance Code Readability, Python Programming, Jupyter Notebook, Data Visualization (DataViz), and Coding.
- Go Beyond the Numbers: Translate Data into Insights: Approx. 28 hours to complete. SKILLS YOU WILL GAIN: Python Programming, Tableau Software, Data Visualization (DataViz), Effective Communication, and Exploratory Data Analysis.
- The Power of Statistics: Approx. 33 hours to complete. SKILLS YOU WILL GAIN: Statistical Analysis, Python Programming, Effective Communication, Statistical Hypothesis Testing, and Probability Distribution.
- Regression Analysis: Simplify Complex Data Relationships: Approx. 28 hours to complete. SKILLS YOU WILL GAIN: Predictive Modelling, Statistical Analysis, Python Programming, Effective Communication, and regression modeling.
- The Nuts and Bolts of Machine Learning: Approx. 33 hours to complete. SKILLS YOU WILL GAIN: Predictive Modelling, Machine Learning, Python Programming, Stack Overflow, and Effective Communication.
- Google Advanced Data Analytics Capstone: Approx. 9 hours to complete. SKILLS YOU WILL GAIN: Executive Summaries, Machine Learning, Python Programming, Technical Interview Preparation, and Data Analysis.
It could be the perfect way to take your skills to the next level! When it comes to investing, there’s no better investment than investing in yourself and your education. Don’t hesitate – go ahead and take the leap. The benefits of learning and self-improvement are immeasurable.
Here are some additional articles that you might find interesting or helpful to read:
- What are quartiles, deciles and percentiles in statistics?
- Standard deviation and variance in statistics
- Skewness for a data distribution
- Kurtosis for a data distribution
- Interpretation of Covariance and Correlation
- Normalization vs Standardization
- What is hypothesis testing in data science?
- Statistics Interview Questions 101
Check out the table of contents for Product Management and Data Science to explore those topics.
Curious about how product managers can utilize Bhagwad Gita’s principles to tackle difficulties? Give this super short book a shot. This will certainly support my work.
Its really a nice article read. Thanks for sharing such beautiful stuffs.
Thank you for posting this. It’s really good
Hey very interesting blog!
yes it’s true really this is nice article