
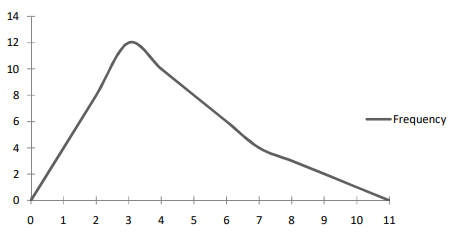
A lack of symmetry is called skewness for data distribution. In other words, a departure from symmetry is called skewness.
A distribution is simply a collection of data, or scores, on a variable. Usually, these scores are arranged in order from smallest to largest and then they can be presented graphically.
Page 6, Statistics in Plain English, Third Edition, 2010.
Skewness
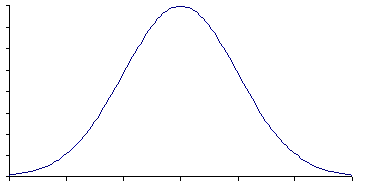
Let’s look at pictures of a Symmetric curve:
The measure of skewness gives the direction and the magnitude of the lack of symmetry.
If the distribution is not symmetric, the frequencies will not be uniformly distributed about the center of the distribution. We will look at pictures of asymmetric distributions shortly.
In mathematics, a figure is called symmetric if there exists a point in it through which if a perpendicular is drawn on the X-axis, it divides the figure into two congruent parts i.e. identical in all respect or one part can be superimposed on the other i.e mirror images of each other.
In Statistics, a distribution is called symmetric if the mean, median, and mode coincide. Otherwise, the distribution becomes asymmetric.
Skewness is a measure of symmetry, or more precisely, the lack of symmetry. A distribution, or data set, is symmetric if it looks the same to the left and right of the center point.
If the distribution is not symmetric, the frequencies will not be uniformly distributed about the center of the distribution.
Let’s look at pictures of asymmetric distributions:
If the right tail is longer, we get a positively skewed distribution for which mean > median > mode:

If the left tail is longer, we get a negatively skewed distribution for which mean < median < mode:

Skewness gives the direction of variability.
Measures of skewness help us to know to what degree and in which direction (positive or negative) the frequency distribution has a departure from symmetry.
Although positive or negative skewness can be detected graphically depending on whether the right tail or the left tail is longer, we don’t get an idea of the magnitude.
The following are the absolute measures of skewness:
1. Skewness (Sk) = Mean – Median
2. Skewness (Sk) = Mean – Mode
3. Skewness (Sk) = (Q3 – Q2) – (Q2 – Q1)
For comparison to series, we do not calculate these absolute measures. We calculate the relative measures which are called the coefficient of skewness. The coefficient of skewness is pure numbers independent of units of measurement.
Relative Measures of Skewness
Karl Pearson’s Coefficient of Skewness
This method is most frequently used for measuring skewness. The formula for measuring the coefficient of skewness is given by:
Sk = (Mean-Mode) / standard deviation
The value of this coefficient would be zero in a symmetrical distribution. If the mean is greater than the mode, the coefficient of skewness would be positive otherwise negative. The value of Karl Pearson’s coefficient of skewness usually lies between 1 for moderately skewed distribution.
If the value of mean, median, and mode are the same in any distribution, then the skewness does not exist in that distribution. Larger the difference in these values, the larger the skewness.
If sum of the frequencies are equal on both sides of the mode then skewness does not exist.
If the distance of the first quartile and third quartile are the same from the median then a skewness does not exist. Similarly, if deciles (first and ninth) and percentiles (first and ninety-nine) are at an equal distance from the median. Then there is no asymmetry.
If a graph of data becomes a normal curve and when it is folded in middle and one part overlaps fully with the other one then there is no asymmetry.
Conclusion
Skewness refers to the extent to which the data is asymmetrical or skewed to one side. It helps to identify whether a distribution is symmetric or skewed. Hope this article had helped in shedding some light on “skewness for a data distribution”.
I highly recommend checking out this incredibly informative and engaging professional certificate Training by Google on Coursera:
Google Advanced Data Analytics Professional Certificate
There are 7 Courses in this Professional Certificate that can also be taken separately.
- Foundations of Data Science: Approx. 21 hours to complete. SKILLS YOU WILL GAIN: Sharing Insights With Stakeholders, Effective Written Communication, Asking Effective Questions, Cross-Functional Team Dynamics, and Project Management.
- Get Started with Python: Approx. 25 hours to complete. SKILLS YOU WILL GAIN: Using Comments to Enhance Code Readability, Python Programming, Jupyter Notebook, Data Visualization (DataViz), and Coding.
- Go Beyond the Numbers: Translate Data into Insights: Approx. 28 hours to complete. SKILLS YOU WILL GAIN: Python Programming, Tableau Software, Data Visualization (DataViz), Effective Communication, and Exploratory Data Analysis.
- The Power of Statistics: Approx. 33 hours to complete. SKILLS YOU WILL GAIN: Statistical Analysis, Python Programming, Effective Communication, Statistical Hypothesis Testing, and Probability Distribution.
- Regression Analysis: Simplify Complex Data Relationships: Approx. 28 hours to complete. SKILLS YOU WILL GAIN: Predictive Modelling, Statistical Analysis, Python Programming, Effective Communication, and regression modeling.
- The Nuts and Bolts of Machine Learning: Approx. 33 hours to complete. SKILLS YOU WILL GAIN: Predictive Modelling, Machine Learning, Python Programming, Stack Overflow, and Effective Communication.
- Google Advanced Data Analytics Capstone: Approx. 9 hours to complete. SKILLS YOU WILL GAIN: Executive Summaries, Machine Learning, Python Programming, Technical Interview Preparation, and Data Analysis.
It could be the perfect way to take your skills to the next level! When it comes to investing, there’s no better investment than investing in yourself and your education. Don’t hesitate – go ahead and take the leap. The benefits of learning and self-improvement are immeasurable.
You may also like:
- What are quartiles, deciles and percentiles in statistics?
- Standard deviation and variance in statistics
- What is data distribution in machine learning?
- Kurtosis for a data distribution
- Interpretation of Covariance and Correlation
- Lorenz Curve and Gini Coefficient Explained
- Normalization vs Standardization
- What is hypothesis testing in data science?
- What do you mean by Weight of Evidence (WoE) and Information Value (IV)?
- Statistics Interview Questions 101
Check out the table of contents for Product Management and Data Science to explore those topics.
Curious about how product managers can utilize Bhagwad Gita’s principles to tackle difficulties? Give this super short book a shot. This will certainly support my work.
Thanks a ton for visiting this website.