

Let’s begin this post with a question: What do you mean by Weight of Evidence (WoE) and Information Value (IV)? This question contains two terms: Weight of Evidence (WoE) & Information Value (IV).
Don’t worry if you don’t have any idea. During this post, we are going to attempt to find out the solution to the question. We will also learn the ways we use WoE & IV in predictive modeling.
Introduction
Generally, we use the logistic regression model (a statistical technique) for solving binary classification problems. For example, credit risk modeling or churn analysis.
These 2 ideas – the weight of evidence (WOE) and information value (IV) evolved from the same logistic regression technique.
Attribute Relevance Analysis
Attribute relevance analysis has two vital functions:
- First, recognition of variables with the greatest impact on target variable
- Second, understanding relations between important predictors and target-variable.
In order to run the above two analyses, we can use the Information Value (IV) and Weight of Evidence (WoE) approach. Specifically, when it comes to classification problems, we use WoE and IV.
WoE and IV can tell stories between an independent variable and a collection of dependent variables. They provide a decent framework for the exploratory analysis of data.
Within the world of credit risk analysis, we have been extensively using WoE and IV for many decades.
In credit risk, we label customers either ‘good’ or ‘bad’, which is predicted on the defaulting credit repayment.
We also record their associated variables, such as age.
Binning of Categorical Features
First, let’s talk about categorical features.
For categorical features, the levels within a feature often do not have an ordinal meaning. So, we need to transform it by either one-hot encoding or hashing. Though such transformations convert the feature into vectors and can be fed into machine learning (ML) algorithms. The 0-1 (binary) valued vectors are tough to interpret as a feature.
For example, some e-commerce companies might want to predict the conversion rate of a bunch of consumers. For this use case, one can extract demographic information of individuals such as the zip code of their addresses, area name, etc. We can treat the zip code as a categorical feature and encoded into a one-hot vector. But, it is not clear which zip code has an inclination for a relatively higher or lower conversion rate.
In such a case, WOE can provide a score for each postcode and one can clearly make out the linkage of a postcode with the conversion rate.
Moreover, we can use this linkage or inclination generated by WOE for feature transformation. Thus, it will profit the model training.
Binning of Numerical Features
Now, let’s talk about numerical features.
For numerical features, though there’s a natural ordering for various numerical values, sometimes nonlinearity exists. In such cases, a linear model fails to capture that nonlinearity.
For example, the average income for a bunch of individuals could increase by time within the age range 20-60. But, might drop after the age of 60 (because of retirement after that).
In such cases, WOE provides scores for each truncated phase (e.g. 30-40, 40-50, …, 60-70) which can process the nonlinearity of the data.
At the heart of IV & WOE methodology, there are groups (bins) of observations.
Note:
- For categorical variables, usually, each category is a bin. However, we can group some smaller categories together.
- For continuous variables, we need to be split into categories.
Weight of Evidence (WoE) Encoding
After that, we bin/group values of variables (continuous and categorical) in line with the subsequent rules:
- First, each bin should have at least 5% of the observations
- Second, each bin should be non-zero for both non-events and events
- Third, The WOE should be monotonic, i.e. either growing or decreasing with the groupings
- Last, we should bin missing values separately
The weight of evidence measures the predictive power of an independent variable in relation to the dependent variable. It has its roots in the credit scoring world and it tells the degree of the separation of good and bad customers. “Good Customers” refers to the customers who pay back loans (non-events) and “Bad Customers” refers to the customers who fall behind with paying a loan (events).
(according to listendata.com)
Post binning, the categorical and numerical columns get transformed into bins/groups i.e. categorical variables.
Then, we need to encode them. So, Weight of evidence (WOE) is a technique used to encode categorical variables for classification.
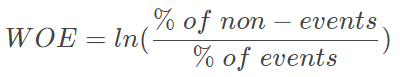
Information Value (IV)
In fact, another helpful & useful byproduct of WOE analysis is Information Value (IV). In general, this measures the importance of a feature.
Another key point, IV depends solely on frequency counting and does not need to fit a model to obtain an attribute importance score.
Information Value gives a measure of how variable X is good in distinguishing between a binary response (e.g. “good” versus “bad”) in some target variable Y. Low Information Value of a variable X means that it may not classify the target variable on a sufficient level and should be removed as an explanatory variable.
(source: stackexchange.com)
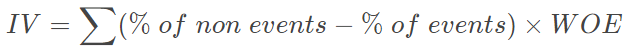
This may be able to combine different WoEs underneath the same independent variable together. The continuous variables are binned such that its IV (information value) is maximized.
Another key purpose, WOE is a transformation to make the predictor variable linear.
Should be remembered, IV is used to select certain variables that go into the logistic model.
If the IV statistic is:
- Less than 0.02, then the predictor is not useful for modeling (separating the Goods from the Bads)
- 0.02 to 0.1, then the predictor has only a weak relationship to the Goods/Bads odds ratio
- 0.1 to 0.3, then the predictor has a medium-strength relationship to the Goods/Bads odds ratio
- 0.3 to 0.5, then the predictor has a strong relationship to the Goods/Bads odds ratio.
- > 0.5, suspicious relationship (Check once)
Python Code
import numpy as np
import pandas as pd
np.random.seed(100)
df = pd.DataFrame({'grade': np.random.choice(list('ABCD'),size=(20)),
'pass': np.random.choice([0,1],size=(20))
})
feature,target = 'grade','pass'
df_woe_iv = (pd.crosstab(df[feature],df[target],
normalize='columns')
.assign(woe=lambda dfx: np.log(dfx[1] / dfx[0]))
.assign(iv=lambda dfx: np.sum(dfx['woe']*
(dfx[1]-dfx[0]))))
df_woe_ivOutput:
pass 0 1 woe iv
grade
A 0.3 0.3 0.000000 0.690776
B 0.1 0.1 0.000000 0.690776
C 0.2 0.5 0.916291 0.690776
D 0.4 0.1 -1.386294 0.690776
This Python code generates a DataFrame df containing randomly generated grades and pass/fail indicators. The grades are represented by letters ‘A’, ‘B’, ‘C’, and ‘D’, and the pass/fail indicators are represented by 0s and 1s.
The code then calculates the weight of evidence (WOE) and information value (IV) for each grade using the pd.crosstab() function from the pandas library. WOE and IV are used in credit risk modeling to determine the predictive power of an independent variable.
The pd.crosstab() function creates a contingency table that shows the frequency of pass/fail for each grade. The normalize='columns' argument normalizes the table by column, which gives the proportion of pass/fail for each grade.
The .assign() method from pandas is then used twice to calculate the WOE and IV for each grade. The WOE is calculated by taking the natural log of the ratio of the proportion of passes to the proportion of fails for each grade. The IV is calculated by multiplying the WOE by the difference between the proportion of passes and the proportion of fails for each grade, and then summing over all grades.
The resulting DataFrame df_woe_iv contains the proportion of passes and fails, WOE, and IV for each grade.
Conclusion
I hope this post has helped you gather some points to answer: “What do you mean by Weight of Evidence (WoE) and Information Value (IV)?”.
Specifically, you learned:
- Attribute relevant analysis to understand the relationship with the target variable
- Binning process of categorical and numerical variables
- WoE encoding of binned variables
- Information values and how to use and interpret them
- Python code snippet to compute WoE & IV
I highly recommend checking out this incredibly informative and engaging professional certificate Training by Google on Coursera:
Google Advanced Data Analytics Professional Certificate
There are 7 Courses in this Professional Certificate that can also be taken separately.
- Foundations of Data Science: Approx. 21 hours to complete. SKILLS YOU WILL GAIN: Sharing Insights With Stakeholders, Effective Written Communication, Asking Effective Questions, Cross-Functional Team Dynamics, and Project Management.
- Get Started with Python: Approx. 25 hours to complete. SKILLS YOU WILL GAIN: Using Comments to Enhance Code Readability, Python Programming, Jupyter Notebook, Data Visualization (DataViz), and Coding.
- Go Beyond the Numbers: Translate Data into Insights: Approx. 28 hours to complete. SKILLS YOU WILL GAIN: Python Programming, Tableau Software, Data Visualization (DataViz), Effective Communication, and Exploratory Data Analysis.
- The Power of Statistics: Approx. 33 hours to complete. SKILLS YOU WILL GAIN: Statistical Analysis, Python Programming, Effective Communication, Statistical Hypothesis Testing, and Probability Distribution.
- Regression Analysis: Simplify Complex Data Relationships: Approx. 28 hours to complete. SKILLS YOU WILL GAIN: Predictive Modelling, Statistical Analysis, Python Programming, Effective Communication, and regression modeling.
- The Nuts and Bolts of Machine Learning: Approx. 33 hours to complete. SKILLS YOU WILL GAIN: Predictive Modelling, Machine Learning, Python Programming, Stack Overflow, and Effective Communication.
- Google Advanced Data Analytics Capstone: Approx. 9 hours to complete. SKILLS YOU WILL GAIN: Executive Summaries, Machine Learning, Python Programming, Technical Interview Preparation, and Data Analysis.
It could be the perfect way to take your skills to the next level! When it comes to investing, there’s no better investment than investing in yourself and your education. Don’t hesitate – go ahead and take the leap. The benefits of learning and self-improvement are immeasurable.
Here are some additional articles that you might find interesting or helpful to read:
- What are quartiles, deciles and percentiles in statistics?
- Standard deviation and variance in statistics
- What is data distribution in machine learning?
- Skewness for a data distribution
- Kurtosis for a data distribution
- Interpretation of Covariance and Correlation
- Lorenz Curve and Gini Coefficient Explained
- Normalization vs Standardization
- What is hypothesis testing in data science?
- Statistics Interview Questions 101
- Logistic Regression for Beginners
- Understanding Confidence Interval, Null Hypothesis, and P-Value in Logistic Regression
- Logistic Regression: Concordance Ratio, Somers’ D, and Kendall’s Tau
Check out the table of contents for Product Management and Data Science to explore those topics.
Curious about how product managers can utilize Bhagwad Gita’s principles to tackle difficulties? Give this super short book a shot. This will certainly support my work.
AI is fun! Thanks a ton for exploring the AI universe by visiting this website.